Complex systems modeling
My methods research agenda spans data science, computational modeling, and applied mathematics. Specifically, I utilize, refine, and innovate machine learning, natural language processing, network analysis, and artificial intelligence tools to dissect and understand complex data sets and systems. My quantitative scholarship revolves around two broader projects: (1) developing and applying computational tools to explore the influence of social relationships and group identities on individual and collective behavior, and (2) leveraging deep learning techniques for data-driven public policy formulation and analysis. For the first project, I use machine learning and network analysis to discover latent relational ties, group affiliations, and ideological communities, subsequently testing various social science theories. For the second, I employ large language models (LLMs) and computer vision to evaluate program effectiveness, support practitioners, and curate valuable data sets. While much of my work has roots in international security and conflict analysis, these methodologies are universally applicable and find their place in my co-authored research across diverse fields.
Multiplex networks
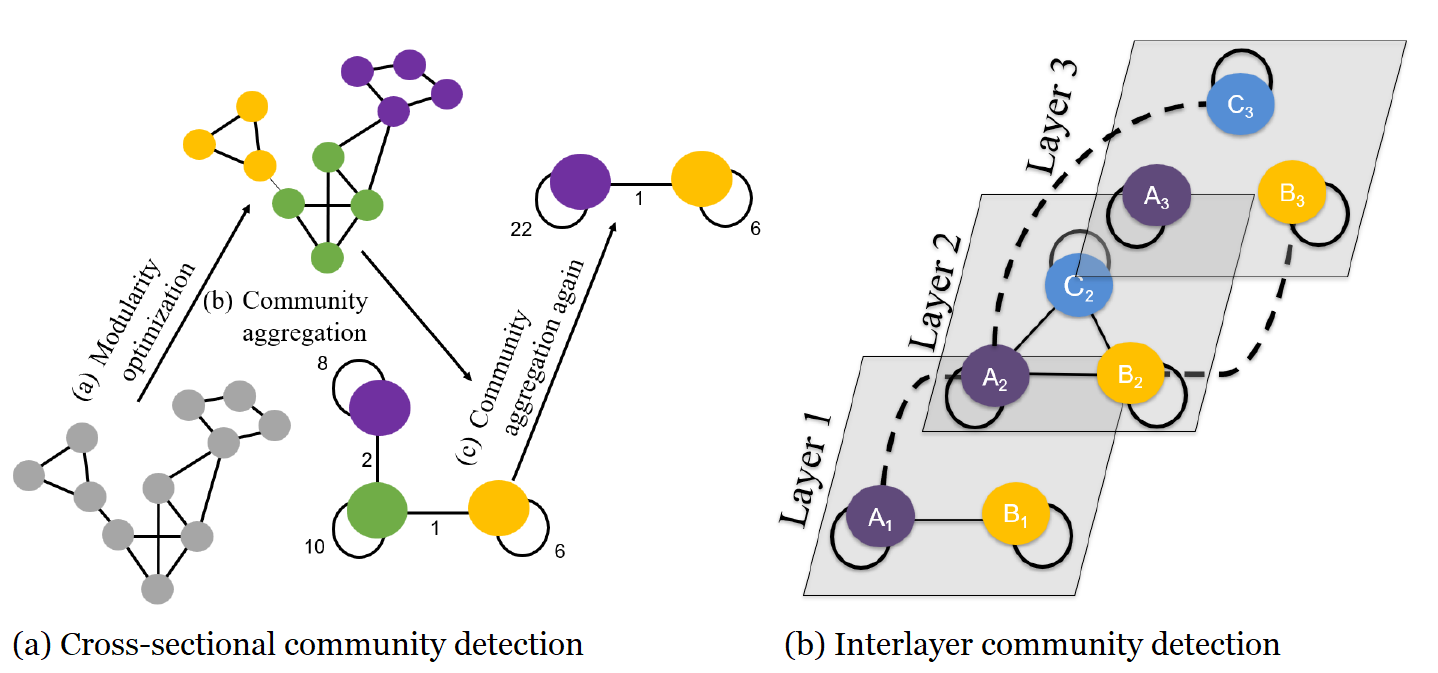
Figure 1: Multiplex community detection algorithm.
I developed a novel multiplex community detection algorithm that is highly efficient for identifying communities in evolving systems. Figure 1 displays an example of my multiplex community detection process. In the first step, I use a cross-sectional community detection algorithm to identify communities within layers. In the second step, I identify shared community membership across t networks---e.g., the number of shared members, Jaccard similarity, or overlap coefficient between communities across network layers. Across simulations and real world examples, my approach more accurately identifies the latent community structure in evolving networks compared to extant multiplex and dynamic stochastic block approaches. I currently writing a manuscript and R statistical package that uses this approach.
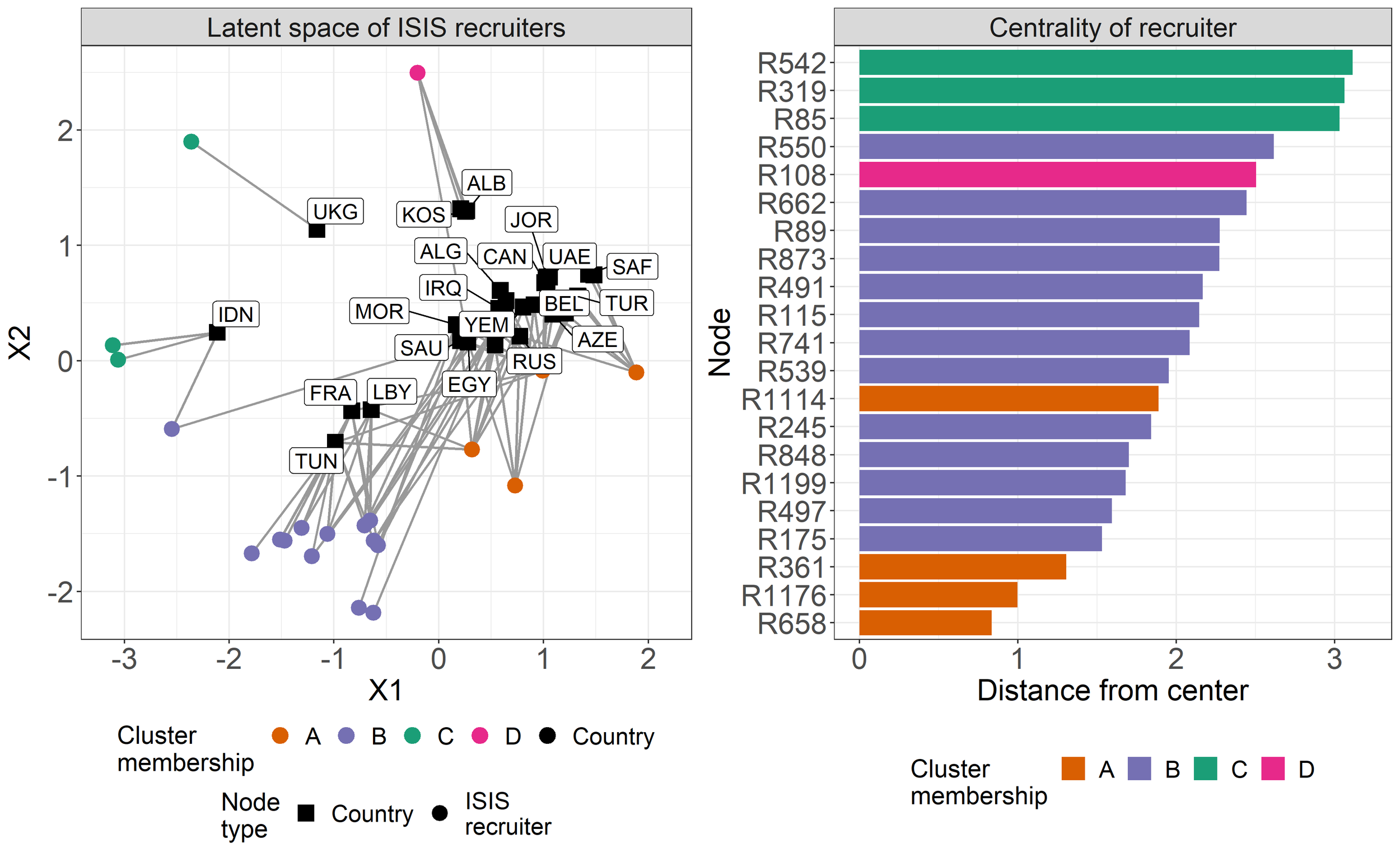
Figure 2: Latent space models to measure the effect of cluster knockouts on network connectivity.
Network knockouts
In work with with Selena Wang (postdoctoral fellow at Yale University), I examine the effect of knockouts and diffusion processes in social systems. In a 2022 Complex Networks article, we develop a novel latent space approach to examine how node knockouts affect overall network connectivity. Using this approach, we find that knocking out sets of Islamic State recruiters decreases expected rebel mobilization (see Figure 2 for the latent space and cluster membership of Islamic State recruiters and countries and their centrality within the network). We are currently extending the approach to measure the effect of node knockouts in temporal network systems. This piece builds on experimental research I have done on network knockouts with Skyler Cranmer published in 2022 Network Science.
Wang and I are also working on extending and validating new network diffusion models. In particular, we are currently testing how a joint latent space and item response model can give researchers insights into how nodes form times with similar nodes and how network connections spread characteristics. In a preliminary analysis of kin relations and node characteristics, we find that suicide bomber mobilization is highly clustered by kin relations, while demographic characteristics are more spread out.
Large language models
In research with Stanford University's HTDL, I use LLMs to classify incoming victim tips to Brazilian law enforcement to try to identify hidden labor trafficking networks. This project is being carried out in conjunction with the Brazilian government. For the initial models, we are using locally trained word embeddings and Portuguese Bidirectional Encoder Representations from Transformer (BERT) to classify victim tips along ten overlapping labels: (1) labor trafficking, (2) child exploitation, (3) unsafe working conditions, (4) labor fraud, (5) public administration violations, (6) workplace discrimination, (7) failure to provide equal opportunity, (8) union violations, (9) failure to comply with COVID-19 precautions, and (10) general labor violations. We have plans to create our own BERT model designed specifically for this purpose. This model and an accompanying manuscript that focuses on classification accuracy is currently in development.
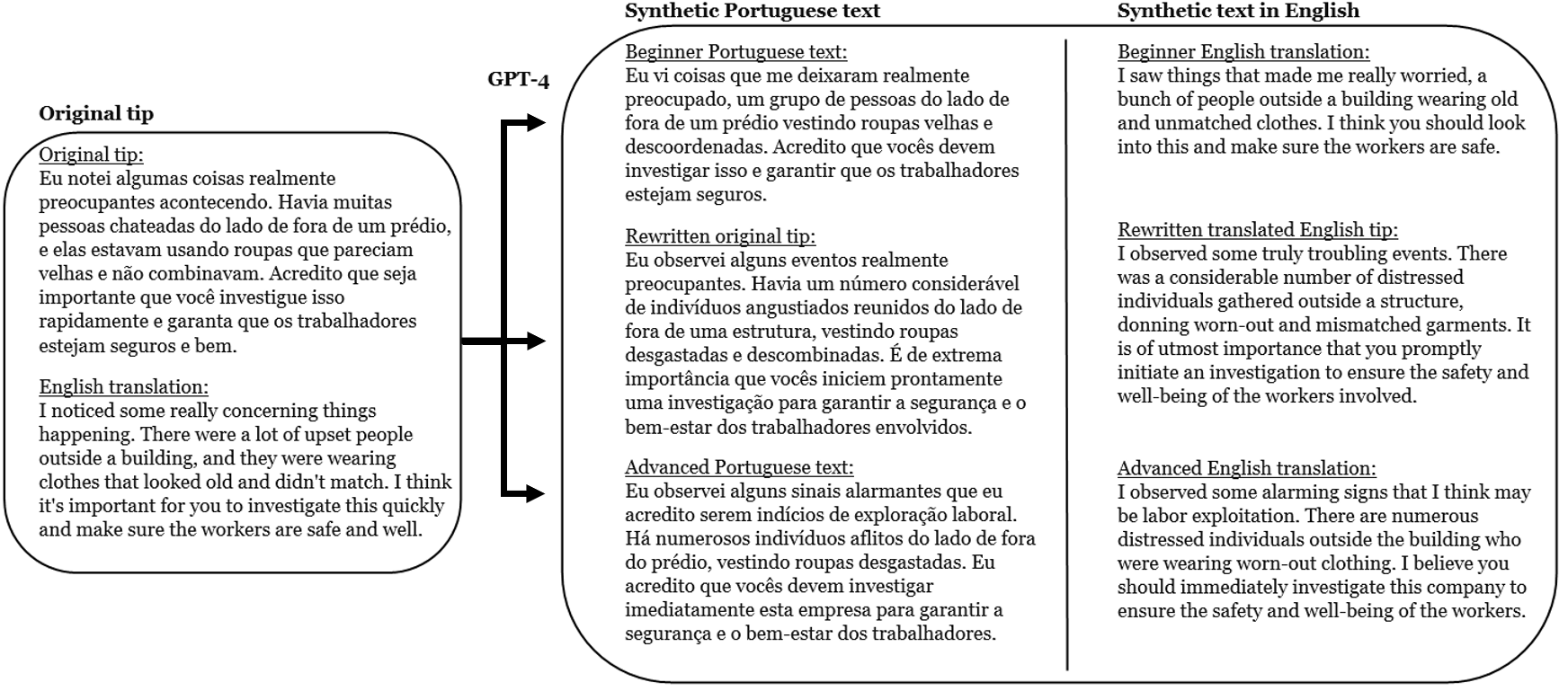
Figure 3: Example of generating synthetic to evaluate how literacy rates affect police response time.
In addition to this paper and project, we are setting up a project where we would use the tip data and LLMs to assess biases in policing responses. To do so, we plan to generate synthetic text using GPT-4 at different literacy levels. With the synthetic text, we assess whether victim tips with “lower literacy levels” receive slower predicted response times. Figure 3 displays an example of the synthetic text generation in Portuguese and English. In the left column, we see an example of a potential tip to law enforcement about labor violations. The right column displays the synthetic text based on tip data at different literacy levels. To complement this analysis, we are developing an experimental design in which respondents will rank the priority of a victim tip where we exogenize the literacy level of the data. Together, these approaches will help us understand how a victim's education and class levels relate to variation in police responsiveness.

Figure 4: Examples of bomb and not bomb crater images.
Computer vision
In collaborative research with Erin Lin (OSU) that builds on a 2020 PlosOne publication, we assess how artificial intelligence can be used to improve classification accuracy with rare events. A prevalent issue in machine learning and image classification is the imbalance between classes in training data, which can bias algorithms toward the majority class. This is especially problematic when the minority class is of significant importance, as is the case with our specific application: detecting bomb craters in satellite imagery. For this project, we use satellite imagery of the Prey Veng province of Cambodia. The available satellite imagery for this province provides us with a dataset where images of bomb craters (the “bombed” class) are rare compared to images without any bomb craters (the: “not bombed” class). Figure 4 displays examples from the training data. To address the class imbalance and improve classification accuracy, we use: Variational Autoencoders (VAEs) and Generative Adversarial Networks (GANs). Both these techniques are adept at generating synthetic images that are statistically similar to the original data. By creating synthetic satellite images of bomb craters, we can effectively upsample the “bombed” class in our training dataset.